
|
|
|
|
|
|
|
|
|
|
|
|
 arXiv 2016 |
 ICCV 2017 |
 |
 |
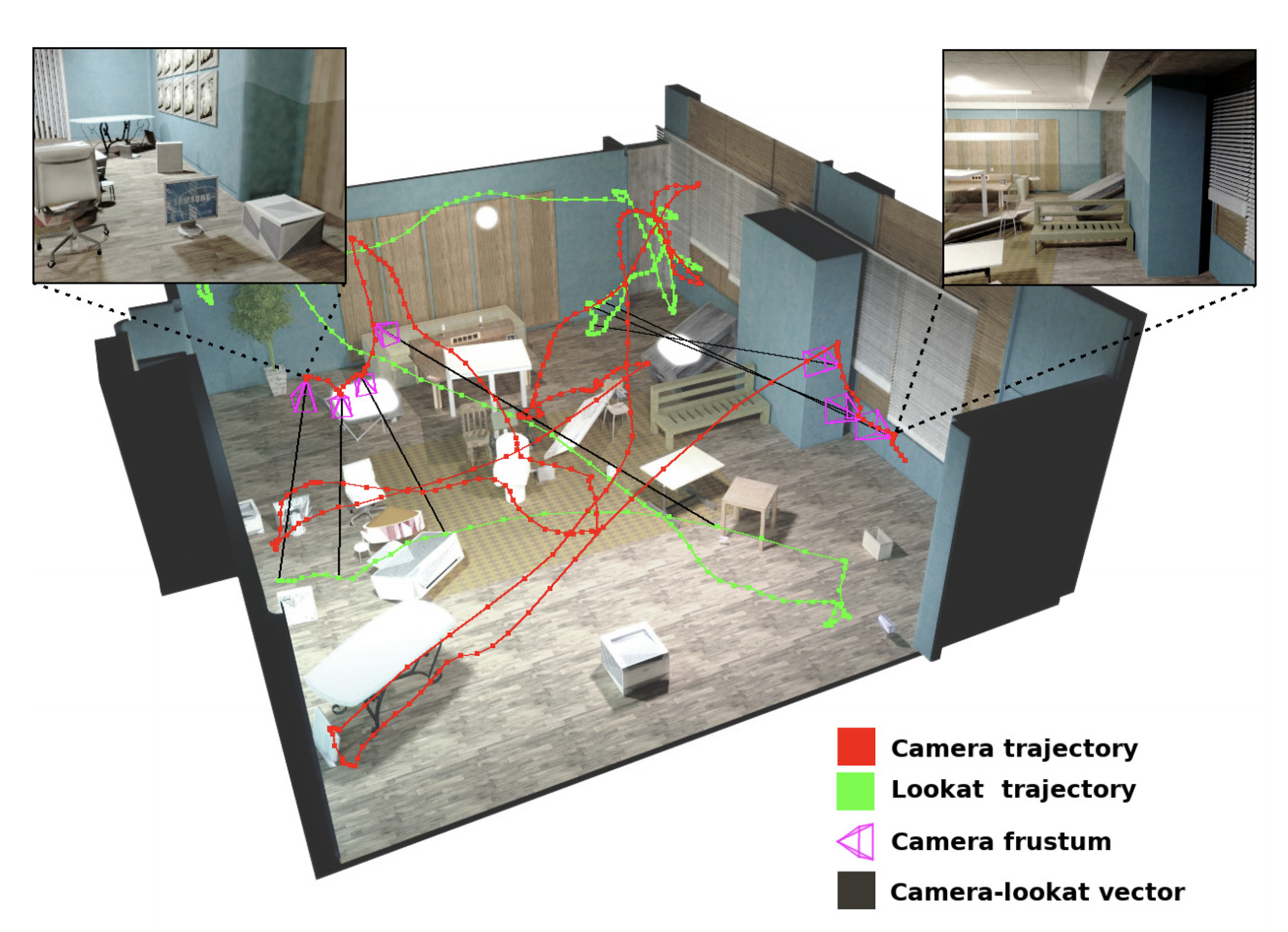
Objects are placed randomly in the scene by dropping them from ceiling and letting them settle down with a physics engine. We used Chrono physics engine to simulate this scenario. Once stable configuration has been generated, we use the poses of the object and render them with NVIDIA OptiX ray tracer.
DatasetTraining Set [263GB] Training Set Protobuf [323MB]Validation Set [15GB] Validation Set Protobuf [31MB] Caveat: Untar-ing can take some time since there are lots of subdirectories. |
Training dataset is also split into 17 tarballstrain_0 [16GB]train_1 [16GB] train_2 [16GB] train_3 [16GB] train_4 [16GB] train_5 [16GB] train_6 [16GB] train_7 [16GB] train_8 [16GB] train_9 [16GB] train_10 [16GB] train_11 [16GB] train_12 [16GB] train_13 [16GB] train_14 [16GB] train_15 [16GB] train_16 [16GB] |
Code to parse the datasethttps://github.com/jmccormac/pySceneNetRGBD |
SUN RGB-D (Alternative links that provide cleaned up dataset)https://github.com/ankurhanda/sunrgbd-meta-data |
NYUv2 (Alternative links that provide cleaned up dataset)https://github.com/ankurhanda/nyuv2-meta-data |
Floor plans from SceneNethttps://drive.google.com/open?id=0B_CLZMBI0zcuRmM4cDIzdUtSdUU |
Code for Generating Scenes and Rendering
Download code for Rendering and Generation |
AcknowledgementsResearch presented in this paper has been supported by Dyson Technology Ltd. We would also like to thank Patrick Bardow for providing optical flow code and Phillip Isola for their neat website template that hosts pix2pix which we modified. |